hadoop 集群搭建
实验室当前hadoop集群节点如下:
| 主机名 | 用户名 | IP | 集群中的角色 |
|---|---|---|---|
| master | hadoop | 10.13.61.122 | NameNode、JobTracker |
| slave1 | hadoop | 10.13.61.125 | DataNode、TaskTracker |
| slave2 | hadoop | 10.13.61.132 | DataNode、TaskTracker |
| slave3 | hadoop | 10.13.61.146 | DataNode、TaskTracker |
| slave4 | hadoop | 10.13.61.144 | DataNode、TaskTracker |
| slave5 | hadoop | 10.13.61.143 | DataNode、TaskTracker |
| slave6 | hadoop | 10.13.61.147 | DataNode、TaskTracker |
| ajm-zju | hadoop | 10.13.61.129 | DataNode、TaskTracker |
各个节点的用户名均设置为 hadoop,密码均为 123456。其中slave3,slave4目前一般不使用。
hadoop集群安装主要有以下几个步骤:
- 环境配置(host设置,ssh免密登录,Java安装等)
- hadoop安装及修改配置文件
- 运行及测试
一、环境配置
1. 用户、主机名、hosts文件
由于目前已经搭建好的hadoop集群的用户名均为hadoop,所以需要在Ubuntu系统上新建一个hadoop用户,步骤如下:
创建hadoop操作用户
1 | sudo useradd -m hadoop -s /bin/bash |
给hadoop用户添加密码
1 | sudo passwd hadoop |
输入密码后回车,密码在输入时是不可见的。
给hadoop用户分配sudo权限
1 | sudo adduser hadoop sudo |
注销或重启系统,以hadoop用户登录
切换用户
1 | su <用户名>,例如 su hadoop; su ajm |
输入要切换的用户密码,即可切换。
安装vim、gedit
vim是命令行编辑工具,gedit是图形界面编辑器,不习惯vim的话建议使用gedit1
2sudo apt-get install vim
sudo apt-get install gedit
修改主机名
不想修改主机名可以跳过此步,不会有影响
在终端中输入hostname可以查看当前主机名,如下图:
实际上在终端中有 hadoop@ajm-zju,其中hadoop是用户名,ajm-zju是主机名
比如要把新的主机加入集群,为了名称统一,可以将主机名改为 slave7,只需:1
2sudo hostname slave7 #暂时生效,重启后会失效
sudo gedit /etc/hostname
在文件中修改为slave7即可
查看本机ip地址
终端中输入以下命令:1
ifconfig
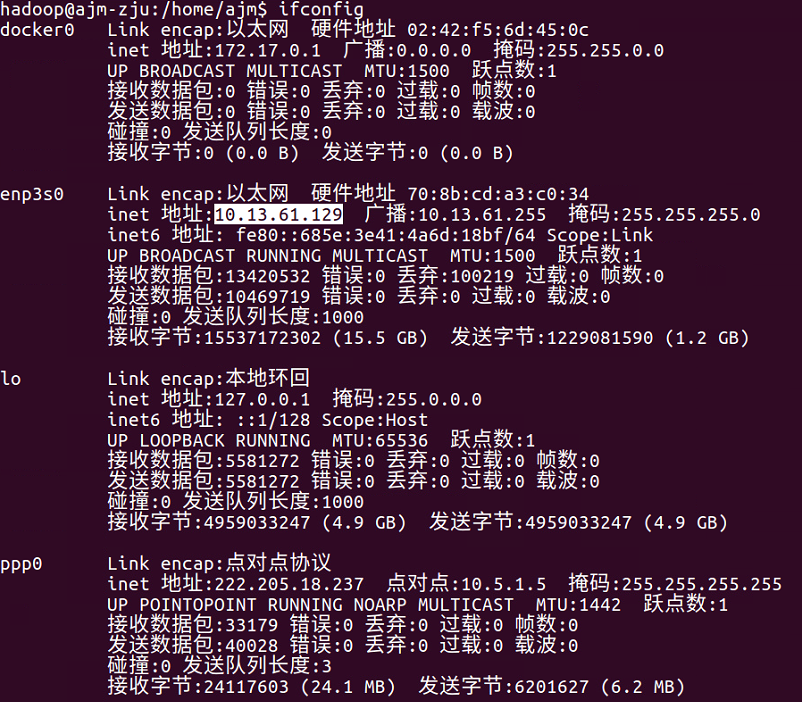
图中的 inet地址: 10.13.61.129 即为本机ip地址。
配置hosts
/etc/hosts文件里维护了主机名和ip地址的映射关系,这样可以直接通过主机名通信,不用每次输入复杂的ip地址。通过cat命令可以直接在命令行中查看文件内容:1
sudo cat /etc/hosts
在我的主机上,结果如下: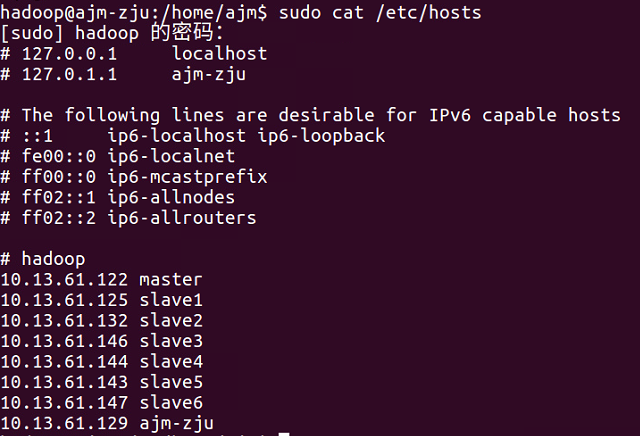
可以hosts文件中保存了hadoop集群中其他主机的 ip地址<->主机名 映射关系,这样在hadoop进行通信时,可以直接通过主机名访问。所以如果集群加入新的主机,需要在新主机上修改hosts文件如上图,并加上本机地址映射1
sudo gedit /etc/hosts
终端中输入以上命令进行修改
测试
如果配置成功,通过 ping 测试时,可以直接通过主机名而不需要ip地址1
2
3ping master
ping slave1
ping 其他主机
成功时结果如下: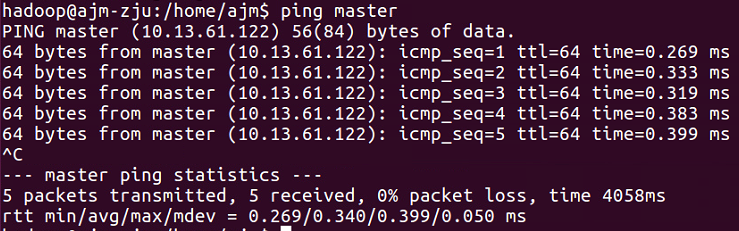
注:ping指令会一直执行,可以通过 ctrl+C 停止
2. 配置SSH免密登录
由于hadoop集群中master主机需要调度各个slave,而这需要配置ssh远程登录服务。
安装ssh
ubuntu 默认安装了ssh 客户端,没有安装服务端。运行:1
ps -e|grep ssh
结果应该与下文类似:1
2hadoop@ajm-zju:/home/ajm$ ps -e|grep ssh
1444 ? 00:00:00 sshd
如果没有 sshd ,则说明没有安装ssh服务端,可以输入以下命令安装:1
sudo apt-get install openssh-server
ssh登录其他主机
1 | ssh master |
出现身份警告时,输入yes并回车,需要输入密码时,请输入master主机的密码。
之后就登录了master主机,可以通过命令行操作maseter主机。
注:退出登录使用exit 命令。
生成RSA公私钥对
但是每次ssh登录都需要输入密码太麻烦,所以可以通过公私钥的方式免密登录,配置方法是 A主机将公钥加入到B主机的authorized_keys中, 则A可以免密登录B。1
2
3ssh-keygen -t rsa # 一路回车
cd ~/.ssh # 公私钥对保存在此目录
ls # 查看目录中的文件列表
终端中输入以上命令后,可以看到有 id_rsa(私钥),id_rsa.pub(公钥)。
则将id_rsa.pub追加到master主机的authorized_keys中,则当前主机可以免密登录master主机。1
ssh-copy-id -i ~/.ssh/id_rsa.pub master
如需要输入密码则输入master主机的密码
ssh免密登录测试
1 | ssh master |
如果直接登录成功,则配置正确。
登录master后,由于master主机已经生成了公私钥对,可以将master的公钥发给当前主机,实现master对当前主机的ssh免密登录。1
ssh-copy-id -i ~/.ssh/id_rsa.pub <hostname>
如果出现错误,则需要在master主机中修改/etc/hosts,添加新主机的 ip<->hostname 映射。
3. java安装
下载 jdk-8u101.linux-x64.tar.gz,运行以下命令解压到/usr目录下:1
2
3
4sudo mkdir /usr/java
sudo tar -zxvf jdk-8u101.linux-x64.tar.gz -C /usr/java
cd /usr/java/jdk1.8.0_101/bin
./java -version #查看java版本

出现上图结果则正确安装
配置环境变量
在前面是通过./java 执行java可执行程序,但是为了执行这个程序,必须每次都切换到/usr/java/jdk1.8.0_101/bin目录下,为了能在任何目录下都能执行java的相关程序,需要配置环境变量。1
sudo gedit /etc/profile
在/etc/profile文件末尾添加如下1
2
3
4export JAVA_HOME=/usr/java/jdk1.8.0_101
export JRE_HOME=/usr/java/jdk1.8.0_101/jre
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
保存后退出。通过source命令使得上面的修改生效。1
source /etc/profile
输入以下命令测试是否成功配置环境变量1
java -version

出现以上结果则成功配置。
二、Hadoop安装
1. 安装及环境变量配置
安装
将hadoop-2.6.0.tar.gz解压到目录/opt1
2
3sudo tar -zxvf hadoop-2.6.0.tar.gz -C /opt # 解压到/opt
cd /opt # 切到含有hadoop-2.6.0的目录下
sudo chown -R hadoop:hadoop ./hadoop-2.6.0 # 修改文件权限
配置环境变量
与java配置环境变量相同,在/etc/profile中追加:1
2
3
4
5export HADOOP_HOME=/opt/hadoop-2.6.0
export HADOOP_LIB_NATIVE=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/lib
保存后退出。通过source命令使得上面的修改生效。1
source /etc/profile
输入以下命令测试是否成功配置环境变量1
hadoop version
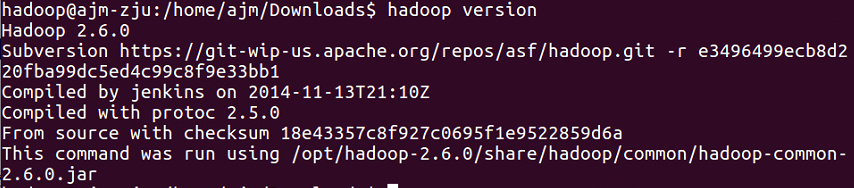
出现以上结果则成功配置。
2. 配置参数
需要对所有的集群节点配置参数,其中大部分文件都是相同的,可以配置一个之后直接复制覆盖相关文件,而比如不同主机java安装路径不同的话,需要复制之后修改hadoop-env.sh和yarn-env.sh的相关参数。
hadoop需要配置一些参数才能成功运行,这些配置文件都在/opt/hadoop-2.6.0/etc/hadoop/ 目录下。
hadoop-env.sh and yarn-env.sh
在hadoop-env.sh和yarn-env.sh中需要指定java安装目录。在文件末尾追加以下内容即可:1
export JAVA_HOME=/usr/java/jdk1.8.0_101
slaves
slaves文件需要添加所有的slave节点主机名如下:1
2
3
4
5
6
7
8slave1
slave2
slave3
slave4
slave5
slave6
ajm-zju
<Your hostname>
core-site.xml
添加以下内容:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
<description></description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-2.6.0/tmp</value>
<description>A base for other temporary directories.</description>
</property>
</configuration>
hdfs-site.xml
这个文件配置hdfs文件系统相关参数,添加以下内容:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-2.6.0/dfs/name</value>
<description>namenode上存储hdfs name空间元数据</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-2.6.0/dfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
mapred-site.xml
这个文件配置mapreduce任务相关参数。首先需要重命名mapred-site.xml.template文件:1
mv ./mapred-site.xml.template mapred-site.xml
然后将以下内容添加到 mapred-site.xml:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.itermediate-done-dir</name>
<value>${hadoop.tmp.dir}/mr-history/tmp</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>${hadoop.tmp.dir}/mr-history/done</value>
</property>
<property>
<name>mapreduce.jobtracker.staging.root.dir</name>
<value>/user</value>
</property>
</configuration>
yarn-site.xml
这个文件配置yarn资源管理调度的相关参数,添加以下内容:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/user</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
</configuration>
三、 运行及测试
ssh登录master主机后,进行以下操作。
格式化分布式文件系统(已有hadoop系统请跳过这一步)
只有在第一次搭建hadoop系统时需要进行格式化操作,请不要在已有的hadoop系统上格式化,这会删除所有的数据!!!!1 | hdfs namenode -format |
运行文件系统管理器hdfs
1 | start-dfs.sh |
运行任务调度管理器yarn
1 | start-yarn.sh |
查看相关进程
1 | jps |
在master中可以看到:1
2
3
4
5
6[hadoop@master ~]$ jps
5859 SecondaryNameNode
6003 ResourceManager
6293 Jps
24991 JobHistoryServer
5695 NameNode
在各个slave中可以看到:1
2
3
4hadoop@ajm-zju:/$ jps
28976 DataNode
31952 NodeManager
32158 Jps
Web查看信息
在web上可以看到集群启动的信息:
- 查看hdfs: master:50070
- 查看resourcemanager: master:8088
如果web页面访问不了,可能是master主机的防火墙未关闭, ssh登录master主机,运行以下命令:1
sudo systemctl status firewalld.service # 查看防火墙状态
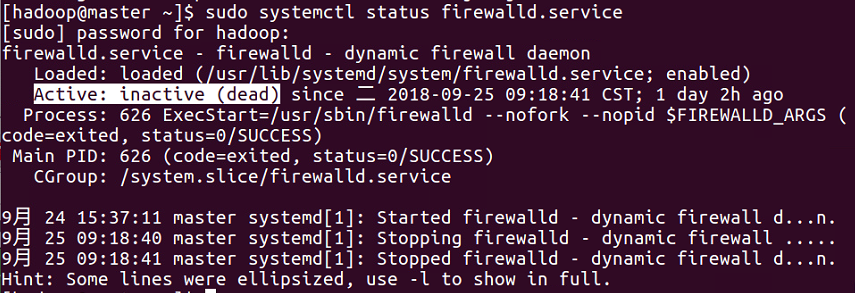
若图中的Active:显示为active,则需要关闭防火墙。1
sudo systemctl stop firewalld.service # 关闭防火墙
关闭后重新访问页面即可。
关闭hadoop
执行相反的操作1
2stop-yarn.sh
stop-dfs.sh
本文引用了以下内容